发表自话题:512的暗示
第一部分
我们对计算机系统的探索是从学习计算机本身开始的,它由处理器和存储器子系统组成。在核心部分,我们需要方法来表示基本数据类型,比如整数和实数运算的近似值。然后,我们考虑机器级指令如何操作这样的数据,以及编译器又如何将c程序翻译成这样的指令。接下来,研究几种实现处理器的方法,帮助我们更好地了解硬件资源如何被用来执行指令。一旦理解了编译器和机器级代码,我们就能了解如何通过编写C程序以及编译它们来最大化程序的性能。本部分以存储器子系统的设计作为结束,这是现代计算机系统最复杂的部分之一。
本书的这一部分将领着你深入了解如何表示和执行应用程序。你将学会一些技巧,来帮助你写出安全、可靠且充分利用计算资源的程序。
第2章 信息的表示和处理
现代计算机存储和处理的信息以二值信号表示。这些微不足道的二进制数字,或者称为位 (bit),形成了数字革命的基础。大家熟悉并使用了1000多年的十进制 (以10为基数) 起源于印度,在12世纪被阿拉伯数学家改进,并在13世纪被意大利数学家 Leonardo Pisano (大约公元1170—1250,更为大家所熟知的名字是Fibonacci) 带到西方。对于有10个手指的人类来说,使用十进制表示法是很自然的事情,但是当构造存储和处理信息的机器时,二进制值工作得更好。二值信号能够很容易地被表示、存储和传输,例如,可以表示为穿孔卡片上有洞或无洞、导线上的高电压或低电压,或者顺时针或逆时针的磁场。对二值信号进行存储和执行计算的电子电路非常简单和可靠,制造商能够在一个单独的硅片上集成数百万甚至数十亿个这样的电路。
孤立地讲,单个的位不是非常有用。然而,当把位组合在一起,再加上某种解释 (interpretation),即赋予不同的可能位模式以含意,我们就能够表示任何有限集合的元素。比如,使用一个二进制数字系统,我们能够用位组来编码非负数。通过使用标准的字符码,我们能够对文档中的字母和符号进行编码。在本章中,我们将讨论这两种编码,以及负数表示和实数近似值的编码。
我们研究三种最重要的数字表示。无符号 (unsigned) 编码基于传统的二进制表示法,表示大于或者等于零的数字。补码 (two's-complement) 编码是表示有符号整数的最常见的方式,有符号整数就是可以为正或者为负的数字。浮点数 (floating-point) 编码是表示实数的科学记数法的以 2 为基数的版本。计算机用这些不同的表示方法实现算术运算,例如加法和乘法,类似于对应的整数和实数运算。
计算机的表示法是用有限数量的位来对一个数字编码,因此,当结果太大以至不能表示时,某些运算就会溢出 (overflow)。溢出会导致某些令人吃惊的后果。例如,在今天的大多数计算机上 (使用 32 位来表示数据类型 int),计算表达式 200300400*500 会得出结果 -884901888。这违背了整数运算的特性,计算一组正数的乘积不应产生一个负的结果。
另一方面,整数的计算机运算满足人们所熟知的真正整数运算的许多性质。例如,利 用乘法的结合律和交换律,计算下面任何一个C表达式,都会得出结果一884901888:
(500 * 400) * (300 * 200)
((500 * 400) * 300) * 200
((200 * 500) * 300) * 400
400 * (200 * (300 * 500))
计算机可能没有产生期望的结果,但是至少它是一致的!
浮点运算有完全不同的数学属性。虽然溢出会产生特殊的值+∞,但是一组正数的乘积总是正的。由于表示的精度有限,浮点运算是不可结合的。例如,在大多数机器上,C表达式 (3.14+le20) - le20 求得的值会是 0.0,而 3.14 + (le20-le20) 求得的值会是3.14。整数运算和浮点数运算会有不同的数学属性是因为它们处理数字表示有限性的方式不同——整数的表示虽然只能编码一个相对较小的数值范围,但是这种表示是精确的;而浮点数虽然可以编码一个较大的数值范围,但是这种表示只是近似的。
通过研究数字的实际表示,我们能够了解可以表示的值的范围和不同算术运算的属性。为了使编写的程序能在全部数值范围内正确工作,而且具有可以跨越不同机器、操作系统和编译器组合的可移植性,了解这种属性是非常重要的。后面我们会讲到,大量计算机的安全漏洞都是由于计算机算术运算的微妙细节引发的。在早期,当人们碰巧触发了程序漏洞,只会给人们带来一些不便,但是现在,有众多的黑客企图利用他们能找到的任何漏洞,不经过授权就进入他人的系统。这就要求程序员有更多的责任和义务,去了解他们的程序如何工作,以及如何被迫产生不良的行为。
计算机用几种不同的二进制表示形式来编码数值。随着第3章进人机器级编程,你需要熟悉这些表示方式。在本章中,我们描述这些编码,并且教你如何推出数字的表示。通过直接操作数字的位级表示,我们得到了几种进行算术运算的方式。理解这些技术对于理解编译器产生的机器级代码是很重要的,编译器会试图优化算术表达式求值的性能。
我们对这部分内容的处理是基于一组核心的数学原理的。从编码的基本定义开始,然后得出一些属性,例如可表示的数字的范围、它们的位级表示以及算术运算的属性。我们相信从这样一个抽象的观点来分析这些内容,对你来说是很重要的,因为程序员需要对计算机运算与更为人熟悉的整数和实数运算之间的关系有清晰的理解。
旁注 怎样阅读本章本章我们研究在计算机上如何表示数字和其他形式数据的基本属性,以及计算机对这些数据执行操作的属性。这就要求我们深入研究数学语言,编写公式和方程式,以及展示重要属性的推导。
为了帮助你阅读,这部分内容安排如下:首先给出以数学形式表示的属性,作为原理。然后,用例子和非形式化的讨论来解释这个原理。我们建议你反复阅读原理描述和它的示例与讨论,直到你对该属性的说明内容及其重要性有了牢固的直觉。对于更加复杂的属性,还会提供推导,其结构看上去将会像一个数学证明。虽然最终你应该尝试理解这些推导,但在第一次阅读时你可以跳过它们。
我们也鼓励你在阅读正文的过程中完成练习题,这会促使你主动学习,帮助你理论联系实际。有了这些例题和练习题作为背景知识,再返回推导,你将发现理解起来会容易许多。同时,请放心,掌握好高中代数知识的人都具备理解这些内容所需要的数学技能。
C++ 编程语言建立在 C 语言基础之上,它们使用完全相同的数字表示和运算。本章中关于 C 的所有内容对 C++ 都有效。另一方面,Java 语言创造了一套新的数字表示和运算标准。C 标准的设计允许多种实现方式,而Java标准在数据的格式和编码上是非常精确具体的。本章中多处着重介绍了Java支持的表示和运算。
旁注 C编程语言的演变前面提到过,C 编程语言是贝尔实验室的 Dennis Ritchie 最早开发出来的,目的是和 Unix 操作系统一起使用(Unix也是贝尔实验室开发的)。在那个时候,大多数系统程序,例如操作系统,为了访问不同数据类型的低级表示,都必须大量地使用汇编代码。比如说,像malloc库函数提供的内存分配功能,用当时的其他高级语言是无法编写的。
Brian Kernighan和 Dennis Ritchie 的著作的第1版记录了最初贝尔实验室的 C 语言版本。随着时间的推移,经过多个标准化组织的努力,C 语言也在不断地演变。1989 年,美国国家标准学会下的一个工作组推出了 ANSIC 标准,对最初的贝尔实验室的 C 语言做了重大修改。ANSIC 与贝尔实验室的 C 有了很大的不同,尤其是函数声明的方式。Brian Kernighan 和 Dennis Ritchie 在著作的第 2 版中描述了 ANSIC,这本书至今仍被公认为关于 C 语言最好的参考手册之一。
国际标准化组织接替了对 C 语言进行标准化的任务,在 1990 年推出了一个几乎和ANSIC 一样的版本,称为 “ISO C90”。该组织在 1999 年又对 C 语言做了更新,推出 “ISO C99”。在这一版本中,引入了一些新的数据类型,对使用不符合英语语言字符的文本字符串提供了支持。更新的版本2011年得到批准,称为 “ISO C11”,其中再次添加了更多的数据类型和特性。最近增加的大多数内容都可以向后兼容,这意味着根据早期标准(至少可以回溯到ISO C90)编写的程序按新标准编译时会有同样的行为。
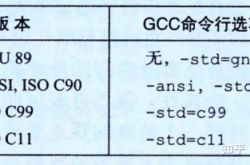
GNU 编译器套装(GNU Compiler Collection,GCC) 可以基于不同的命令行选项,依照多个不同版本的C语言规则来编译程序,如图2-1所示。比如,根据 ISO Cl1来编译程序prog.c,我们就使用命令行
linux> gcc-std=cllprog.c
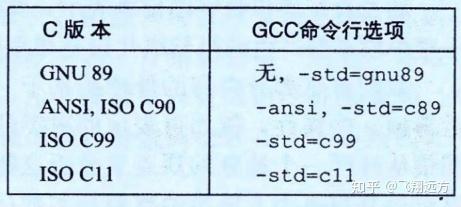
编译选项 -ansi 和 -std=c89 的用法是一样的 —— 会根据ANSI或者 ISO C90 标准来编译程序。(C90有时也称为 “C89”,这是因为它的标准化工作是从1989年开始的。)编译选项 -std=c99 会让编译器按照 ISO C99 的规则进行编译。
本书中,没有指定任何编译选项时,程序会按照基于 ISO C90 的 C 语言版本进行编译,但是也包括一些 C99、C11 的特性,一些 C++ 的特性,还有一些是与 GCC 相关的特性。GNU 项目正在开发一个结合了 ISO C11 和其他一些特性的版本,可以通过命令行选项 -std=gnul1 来指定。(目前,这个实现还未完成。)今后,这个版本会成为默认的版本。
2.1 信息存储
大多数计算机使用8位的块,或者字节 (byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存 (virtual memory)。内存的每个字节都由一个唯一的数字来标识,称为它的地址 (address),所有可能地址的集合就称为虚拟地址空间(virtual address space)。顾名思义,这个虚拟地址空间只是一个展现给机器级程序的概念性映像。实际的实现(见第9章)是将动态随机访问存储器(DRAM)、闪存、磁盘存储器、特殊硬件和操作系统软件结合起来,为程序提供一个看上去统一的字节数组。
在接下来的几章中,我们将讲述编译器和运行时系统是如何将存储器空间划分为更可管理的单元,来存放不同的程序对象 (program object),即程序数据、指令和控制信息。可以用各种机制来分配和管理程序不同部分的存储。这种管理完全是在虚拟地址空间里完成的。例如,C 语言中一个指针的值(无论它指向一个整数、一个结构或是某个其他程序对象)都是某个存储块的第一个字节的虚拟地址。C 编译器还把每个指针和类型信息联系起来,这样就可以根据指针值的类型,生成不同的机器级代码来访问存储在指针所指向位置处的值。尽管 C 编译器维护着这个类型信息,但是它生成的实际机器级程序并不包含关于数据类型的信息。每个程序对象可以简单地视为一个字节块,而程序本身就是一个字节序列。
给C语言初学者 C语言中指针的作用指针是 C 语言的一个重要特性。它提供了引用数据结构(包括数组)的元素的机制。与变量类似,指针也有两个方面:值和类型。它的值表示某个对象的位置,而它的类型表示那个位置上所存储对象的类型(比如整数或者浮点数)。
真正理解指针需要查看它们在机器级上的表示以及实现。这将是第3章的重点之一,3.10.1节将对其进行深入介绍。
2. 1. 1 十六进制表示法
一个字节由8位组成。在二进制表示法中,它的值域是 
在C语言中,以 0x 或 0X 开头的数字常量被认为是十六进制的值。字符 ‘A’〜‘F’ 既可以是大写,也可以是小写。例如,我们可以将数字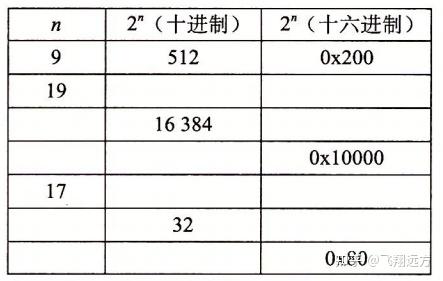
十进制和十六进制表示之间的转换需要使用乘法或者除法来处理一般情况。将一个十进制数字 χ 转换为十六进制,可以反复地用 16 除 χ,得到一个商 q 和一个余数 r,也就是 χ = q * 16 + r。然后,我们用十六进制数字表示的 r 作为最低位数字,并且通过对 q 反复 进行这个过程得到剩下的数字。例如,考虑十进制 314 156的转换:
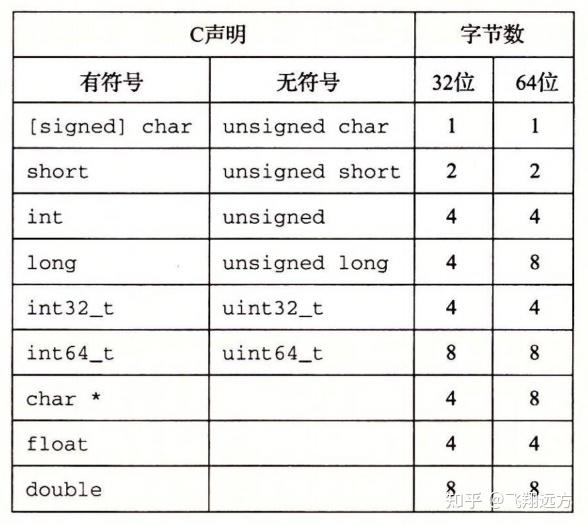
C语言支持整数和浮点数的多种数据格式。图2-3 展示了为 C 语言各种数据类型分配的字节数。(我们在2.2节讨论 C 标准保证的字节数和典型的字节数之间的关系。)有些数据类型的确切字节数依赖于程序是如何被编译的。我们给出的是32位和64位程序的典型值。整数或者为有符号的,即可以表示负数、零和正数;或者为无符号的,即只能表示非负数。C 的数据类型 char 表示一个单独的字节。尽管 “char” 是由于它被用来存储文本串中的单个字符这一事实而得名,但它也能被用来存储整数值。数据类型 short,int 和 long 可以提供各种数据大小。即使是为64位系统编译,数据类型 int 通常也只有 4 个字节。数据类型 long —般在 32位 程序中为 4 字节,在 64 位程序中则为 8 字节。
为了避免由于依赖“典型”大小和不同编译器设置带来的奇怪行为,ISO C99 引入了一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化。其中就有数据类型 int32_t 和 int64_t,它们分别为4个字节和8个字节。使用确定大小的整数类型是程序 员准确控制数据表示的最佳途径。
大部分数据类型都编码为有符号数值,除非有前缀关键字 unsigned 或对确定大小的 数据类型使用了特定的无符号声明。数据类型 char 是一个例外。尽管大多数编译器和机器将它们视为有符号数,但 C 标准不保证这一点。相反,正如方括号指示的那样,程序员应该用有符号字符的声明来保证其为一个字节的有符号数值。不过,在很多情况下,程序行为对数据类型 char 是有符号的还是无符号的并不敏感。
对关键字的顺序以及包括还是省略可选关键字来说,C 语言允许存在多种形式。比 如,下面所有的声明都是一个意思:
unsigned long
unsigned long int
long unsigned
long unsigned int
我们将始终使用图2-3给出的格式。
图2-3还展示了指针(例如一个被声明为类型为“char * ”的变量)使用程序的全字长。大多数机器还支持两种不同的浮点数格式:单精度(在 C 中声明为float)和双精度(在 C 中声明为 double)。这些格式分别使用4字节和8字节。
给C语言初学者 声明指针 对于任何数据类型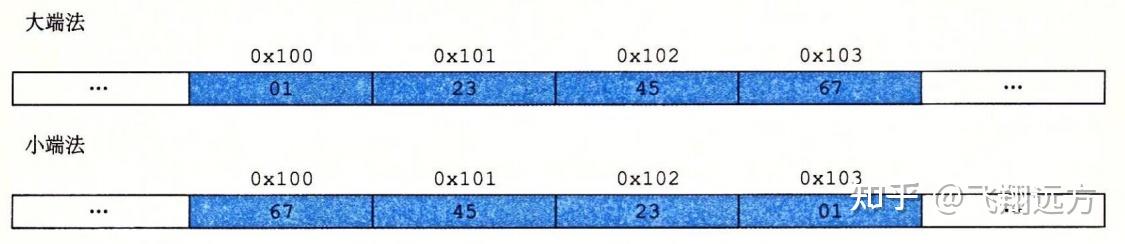
注意,在字 0x01234567 中,高位字节的十六进制值为 0x01,而低位字节值为 0x67。
大多数Intel兼容机都只用小端模式。另一方面,IBM 和 Oracle(从其2010年收购 Sun Microsystems开始)的大多数机器则是按大端模式操作。注意我们说的是“大多数”。这些规则并没有严格按照企业界限来划分。比如,IBM 和 Oracle 制造的个人计算机使用的是 Intel 兼容的处理器,因此使用小端法。许多比较新的微处理器是双端法(bi-endian),也就是说可以把它们配置成作为大端或者小端的机器运行。然而,实际情况是:一旦选择了特定操作系统,那么字节顺序也就固定下来。比如,用于许多移动电话的ARM微处理器,其硬件可以按小端或大端两种模式操作,但是这些芯片上最常见的两种操作系统——Android(来自Google)和 IOS(来自Apple)却只能运行于小端模式。
令人吃惊的是,在哪种字节顺序是合适的这个问题上,人们表现得非常情绪化。实际上,术语 “little endian(小端)” 和 “big endian(大端)” 出自Jonathan Swift的《格利佛游记》(Gulliver's Travels)一书,其中交战的两个派别无法就应该从哪一端(小端还是大端)打开一个半熟的鸡蛋达成一致。就像鸡蛋的问题一样,选择何种字节顺序没有技术上的理由,因此争论沦为关于社会政治论题的争论。只要选择了一种规则并且始终如一地坚持,对于哪种字节排序的选择都是任意的。
旁注 “端”的起源以下是 Jonathan Swift 在 1726 年关于大小端之争历史的描述: “……我下面要告诉你的是,Lilliput 和 Blefuscu 这两大强国在过去36个月里一直在苦战。战争开始是由于以下的原因:我们大家都认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋时碰巧将一个手指弄破了,因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。老百姓们对这项命令极为反感。历史告诉我们,由此曾发生过六次叛乱,其中一个皇帝送了命,另一个丢了王位。这些叛乱大多都是由Blefuscu的国王大臣们煽动起来的。叛乱平息后,流亡的人总是逃到那个帝国去寻救避难。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端。关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派的任何人不得做官。”(此段译文摘自网上蒋剑锋译的《格利佛游记》第一卷第4章。)
在他那个时代,Swift是在讽刺英国 (Lilliput) 和法国 (Blefuscu) 之间持续的冲突。Danny Cohen, 一位网络协议的早期开创者,第一次使用这两个术语来指代字节顺序,后来这个术语被广泛接纳了。
对于大多数应用程序员来说,其机器所使用的字节顺序是完全不可见的。无论为哪种类型的机器所编译的程序都会得到同样的结果。不过有时候,字节顺序会成为问题。首先是在不同类型的机器之间通过网络传送二进制数据时,一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反过来时,接收程序会发现,字里的字节成了反序的。为了避免这类问题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送方机器将它的内部表示转换成网络标准,而接收方机器则将网络标准转换为它的内部表示。我们将在第11章中看到这种转换的例子。
第二种情况是,当阅读表示整数数据的字节序列时字节顺序也很重要。这通常发生在检查机器级程序时。作为一个示例,从某个文件中摘出了下面这行代码,该文件给出了一个针对 Intel x86-64处理器的机器级代码的文本表示:
4004d3: 01 05 43 0b 20 00 add %eax,0x200b43(%rip)这一行是由反汇编器(disassembler)生成的,反汇编器是一种确定可执行程序文件所表示的指令序列的工具。我们将在第3章中学习有关这些工具的更多知识,以及怎样解释像这样的行。而现在,我们只是注意这行表述的意思是:十六进制字节串 01 05 43 0b 20 00 是一条指令的字节级表示,这条指令是把一个字长的数据加到一个值上,该值的存储地址由 0x200b43 加上当前程序计数器的值得到,当前程序计数器的值即为下一条将要执行指令的地址。如果取出这个序列的最后4个字节:43 0b 20 00,并且按照相反的顺序写出,我们得到 00 20 0b 43。去掉开头的 0,得到值0x200b43,这就是右边的数值。当阅读像此类小端法机器生成的机器级程序表示时,经常会将字节按照相反的顺序显示。书写字节序列的自然方式是最低位字节在左边,而最高位字节在右边,这正好和通常书写数字时最高有效位在左边,最低有效位在右边的方式相反。
字节顺序变得重要的第三种情况是当编写规避正常的类型系统的程序时。在 C 语言中,可以通过使用强制类型转换 (cast) 或联合 (union) 来允许以一种数据类型引用一个对象,而这种数据类型与创建这个对象时定义的数据类型不同。大多数应用编程都强烈不推荐这种编码技巧,但是它们对系统级编程来说是非常有用,甚至是必需的。
图2-4 展示了一段 C 代码,它使用强制类型转换来访问和打印不同程序对象的字节表示。我们用 typedef 将数据类型 byte_pointer 定义为一个指向类型为 “unsignedchar” 的对象的指针。这样一个字节指针引用一个字节序列,其中每个字节都被认为是一个非负整数。第一个例程 show_bytes 的输入是一个字节序列的地址,它用一个字节指针以及一个字节数来指示。该字节数指定为数据类型 size_t,表示数据结构大小的首选数据类型。show_bytes 打印出每个以十六进制表示的字节。C 格式化指令 “%.2x” 表明整数必须用至少两个数字的十六进制格式输出。
#include typedef unsigned char *byte_pointer; void show_bytes(byte_pointer start, size_t len) { size_t i; for (i = 0; i < len; i++) printf(" %.2x", start[i]); printf("\n"); } void show_int(int x) { show_bytes((bypte_pointer) &x, sizeof(int)); } void show_float(float x) { show_bytes((byte_pointer) &x, sizeof(float)); } void show_pointer(void *x) { show_bytes((byte_pointer) &x, sizeof(void *)); }图2-4 打印程序对象的字节表示。这段代码使用强制类型转换来规避类型系统。很容易定义针对其他数据类型的类似函数
过程 show_int、show_float 和 show_pointer 展示了如何使用程序 show_bytes 来分别输出类型为int、float和 void * 的 C 程序对象的字节表示。可以观察到它们仅仅传递给 show_bytes 一个指向它们参数 x 的指针 &x,且这个指针被强制类型转换为 "unsigned char * ”。这种强制类型转换告诉编译器,程序应该把这个指针看成指向一个字节序列,而不是指向一个原始数据类型的对象。然后,这个指针会被看成是对象使用的最低字节地址。
这些过程使用C语言的运算符 sizeof 来确定对象使用的字节数。一般来说,表达式 sizeof(T) 返回存储一个类型为 T 的对象所需要的字节数。使用 sizeof 而不是一个固定的值,是向编写在不同机器类型上可移植的代码迈进了一步。
在几种不同的机器上运行如图2-5 所示的代码,得到如图2-6 所示的结果。我们使用 了以下几种机器:
Linux 32:运行 Linux 的 Intel IA32 处理器。
Windows:运行 Windows 的 Intel IA32 处理器。
Sun:运行Solaris的 Sun Microsystems SPARC 处理器。(这些机器现在由Oracle生产。)
Linux 64:运行 Linux 的 Intel x86-64 处理器。
-------------------------------- code/data/show-bytes.c void test_show_bytes(int val) { int ival = val; float fval = (float) ival; int *pval = &ival; show_int(ival); show_float(fval); show_pointer(pval); } -------------------------------- code/data/show-bytes.c图2-5 字节表示的示例,这段代码打印示例数据对象的字节表示
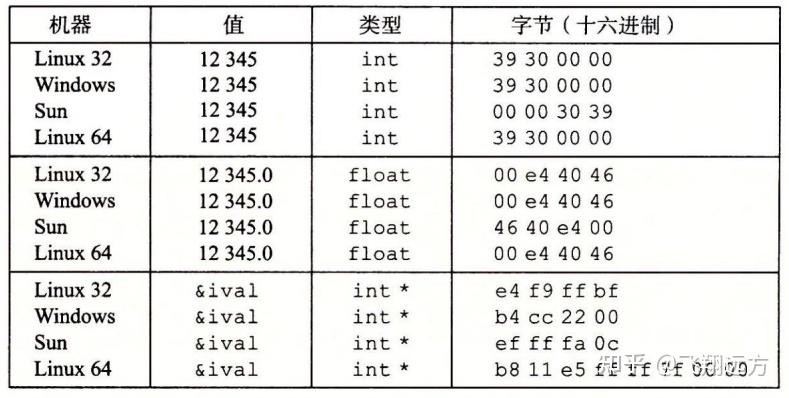
参数12345的十六进制表示为 0x00003039。对于int类型的数据,除了字节顺序以外,我们在所有机器上都得到相同的结果。特别地,我们可以看到在 Linux32、Windows 和 Linux64上,最低有效字节值0x39最先输出,这说明它们是小端法机器;而在Sun 上最后输出,这说明Sun是大端法机器。同样地,float 数据的字节,除了字节顺序以外,也都是相同的。另一方面,指针值却是完全不同的。不同的机器/操作系统配置使用不同的存储分配规则。一个值得注意的特性是 Linux32、Windows 和 Sun的机器使用 4 字节地址,而 Linux64 使用8字节地址。
给C语言初学者 使用 typedef 来命名数据类型C 语言中的 typedef 声明提供了一种给数据类型命名的方式。这能够极大地改善代 码的可读性,因为深度嵌套的类型声明很难读懂。
typedef的语法与声明变量的语法十分相像,除了它使用的是类型名,而不是变量名。因此,图2-4 中 byte_pointer 的声明和将一个变量声明为类型 “unsigned char * ”有相同的形式。
例如,声明:
typedef int *int_pointer;
int_pointer ip;
将类型 “int_pointer” 定义为一个指向int的指针,并且声明了一个这种类型的变量 ip。我们还可以将这个变量直接声明为:
int *ip;
给 C 语言初学者 使用 printf格式化输出
printf函数(还有它的同类 fprintf 和 sprintf )提供了一种打印信息的方式,这种方式对格式化细节有相当大的控制能力。第一个参数是格式串(format string),而其余的参数都是要打印的值。在格式串里,每个以 “%” 开始的字符序列都表示如何格式化下一个参数。典型的示例包括:‘%d’ 是输出一个十进制整数,‘%f’ 是输出一个浮点数,而 ‘%c’ 是输出一个字符,其编码由参数给出。
指定确定大小数据类型的格式,如 int32_t,要更复杂一些,相关内容参见 2.2.3 节的旁注。
可以观察到,尽管浮点型和整型数据都是对数值12345编码,但是它们有截然不同的 字节模式:整型为 0x00003039,而浮点数为 0x4640E400。一般而言,这两种格式使用不同的编码方法。如果我们将这些十六进制模式扩展为二进制形式,并且适当地将它们移位,就会发现一个有13个相匹配的位的序列,用一串星号标识出来:
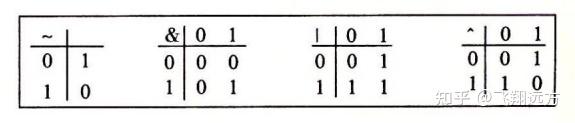
最简单的布尔代数是在二元集合 {0,1} 基础上的定义。图2-7 定义了这种布尔代数中的几种运算。我们用来表示这些运算的符号与 C 语言位级运算使用的符号是相匹配的,这些将在后面讨论到。布尔运算 ~ 对应于逻辑运算 NOT,在命题逻辑中用符号 ﹁ 表示。也就是说,当 P 不是真的时候,我们就说 ﹁P 是真的,反之亦然。相应地,当 P 等于 0 时,~P 等于 1,反之亦然。布尔运算 & 对应于逻辑运算 AND,在命题逻辑中用符号 ∧ 表示。当 P 和 Q 都为真时,我们说 P ∧ Q 为真。相应地,只有当 p=1 且 q=1 时,p&q 才等于 1。布尔运算 | 对应于逻辑运算 OR,在命题逻辑中用符号 ∨ 表示。当 P 或者 Q 为真时,我们说 P ∨ Q 成立。相应地,当 p=1 或者 q=1 时,p|q 等于1。布尔运算 ^ 对应于逻辑运算异或,在命题逻辑中用符号 ㊉ 表示。当 P 或者 Q 为真但不同时为真时,我们说 P㊉Q 成立。相应地,当 p=1 且 q=0,或者 p=0 且 q=1 时,p^q 等于1。
后来创立信息论领域的 Claude Shannon(1916—2001)首先建立了布尔代数和数字逻辑之间的联系。他在 1937 年的硕士论文中表明了布尔代数可以用来设计和分析机电继电器网络。尽管那时计算机技术已经取得了相当的发展,但是布尔代数仍然在数字系统的设计和分析中扮演着重要的角色。
我们可以将上述4个布尔运算扩展到位向量的运算,位向量就是固定长度为 w、由 0 和 1 组成的串。位向量的运算可以定义成参数的每个对应元素之间的运算。假设 a 和 b 分别表示位向量 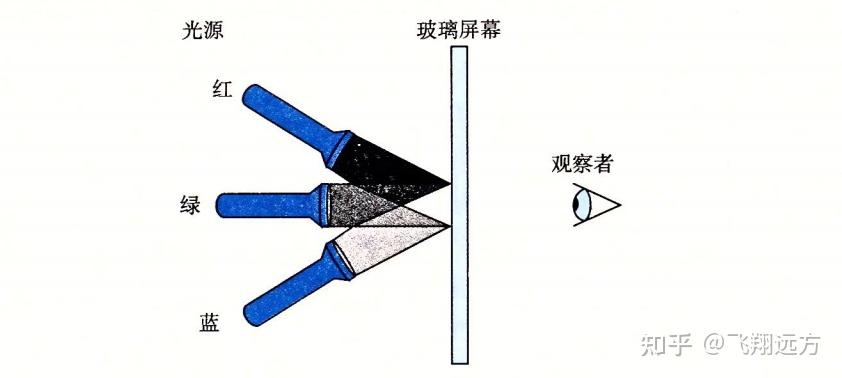
那么基于光源R(红)、G(绿)、B(蓝)的关闭(0)或打开(1),我们就能够创建8种不同的颜色:

这些颜色中的每一种都能用一个长度为3的位向量来表示,我们可以对它们进行布尔运算。
蓝色 | 绿色 =
黄色 & 蓝绿色 =
红色 ^ 红紫色 =
2.1.7 C 语言中的位级运算
C语言的一个很有用的特性就是它支持按位布尔运算。事实上,我们在布尔运算中使 用的那些符号就是 C 语言所使用的:| 就是 OR(或),&就是 AND(与),~ 就是 NOT(取反),而 ^ 就是 EXCLUSIVE-OR(异或)。这些运算能运用到任何“整型”的数据类型上,包括图2-3 所示内容。以下是一些对 char 数据类型表达式求值的例子:
C的表达式二进制表达式二进制结果十六进制结果~0x41~[0100 0001][1011 1110]0xBE~0x00~[0000 0000][1111 1111]0xFF0x69 & 0x55[0110 1001]&[0101 0101][0100 0001]0x410x69 | 0x55[0110 1001][0101 0101][0111 1101]0x7D正如示例说明的那样,确定一个位级表达式的结果最好的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后再转换回十六进制。
✍ 练习题2.10 对于任一位向量a,有 a^a=0。应用这一属性,考虑下面的程序: void inplace_swap(int *x, int *y) {
*y = *x ^ *y; /* Step 1 */
*x = *x ^ *y; /* Step 2 */
*y = *x ^ *y; /* Step 3 */
}
正如程序名字所暗示的那样,我们认为这个过程的效果是交换指针变量x和y所指向的存储位置处存放的值。注意,与通常的交换两个数值的技术不一样,当移动一个值时,我们不需要第三个位置来临时存储另一个值。这种交换方式并没有性能上的优势,它仅仅是一个智力游戏。
以指针 x 和 y 指向的位置存储的值分别是 a 和 b 作为开始,填写下表,给出在程序的每一步之后,存储在这两个位置中的值。利用 ^ 的属性证明达到了所希望的效果。回想一下,每个元素就是它自身的加法逆元(a^a=0)。
void reverse_array(int a[], int cnt) {
int first, last;
for (first = 0, last = cnt-1;
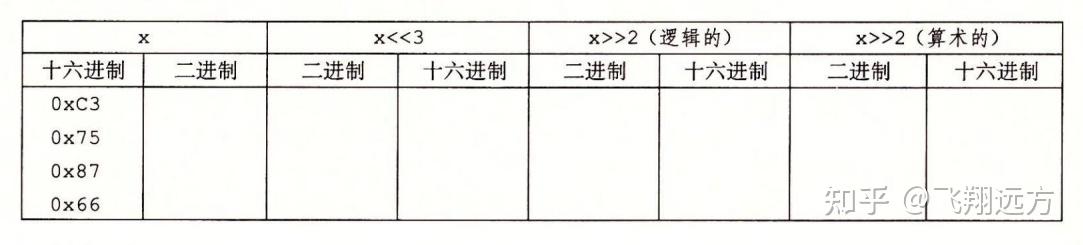
first ,但是它的行为有点微妙。一般而言,机器支持两种形 式的右移:逻辑右移和算术右移。逻辑右移在左端补
标签组:[电脑] [二进制] [指针] [符号计算] [二进制代码] [十六进制] [计算机编码] [二进制编码] [指针变量] [数字转换] [关系运算] [类型系统] [信息存储] [编码转换] [c语言指针] [对象存储] [布尔运算] [编译器优化]
上一篇:商业价值:柳传志的512天