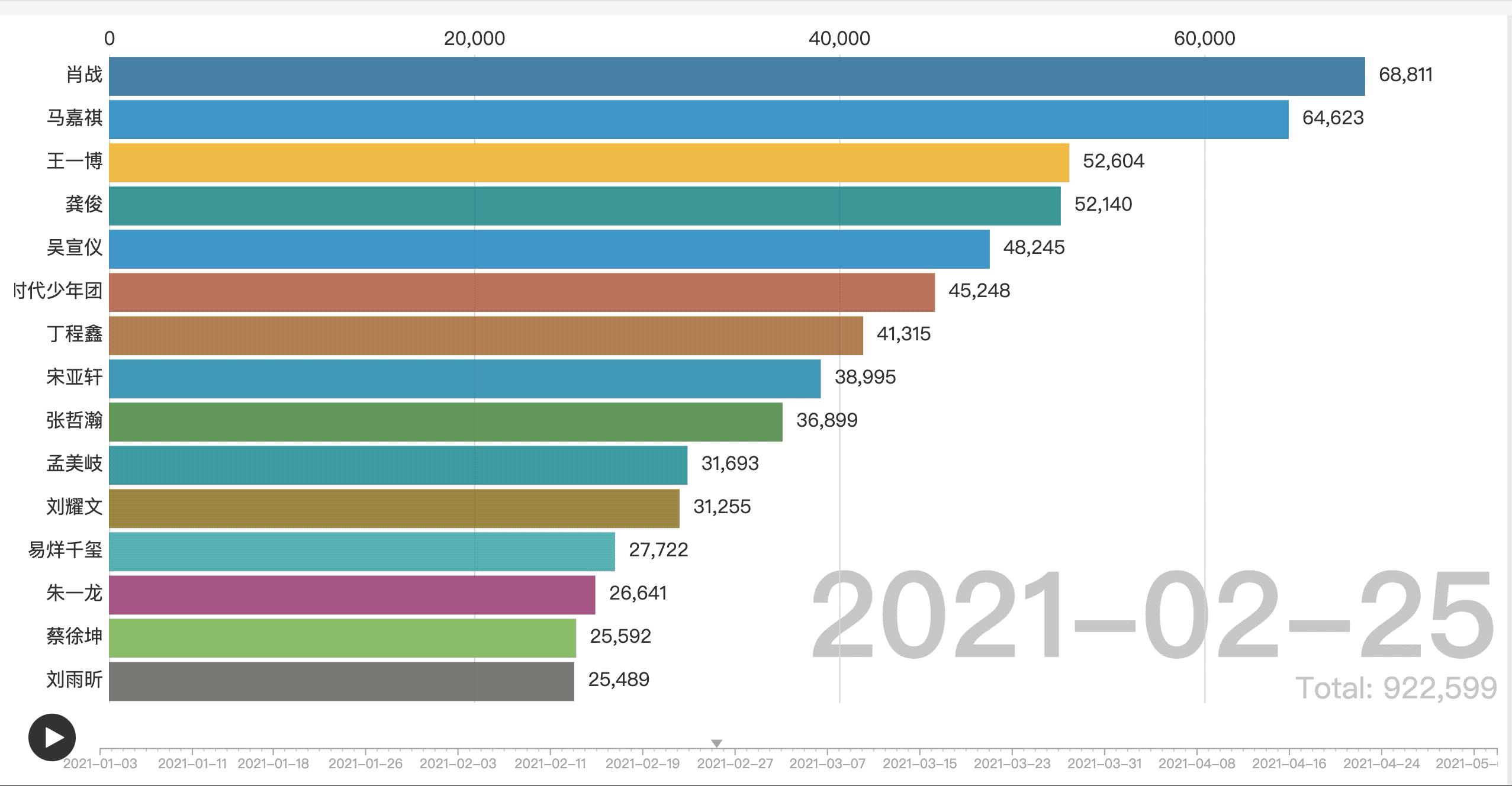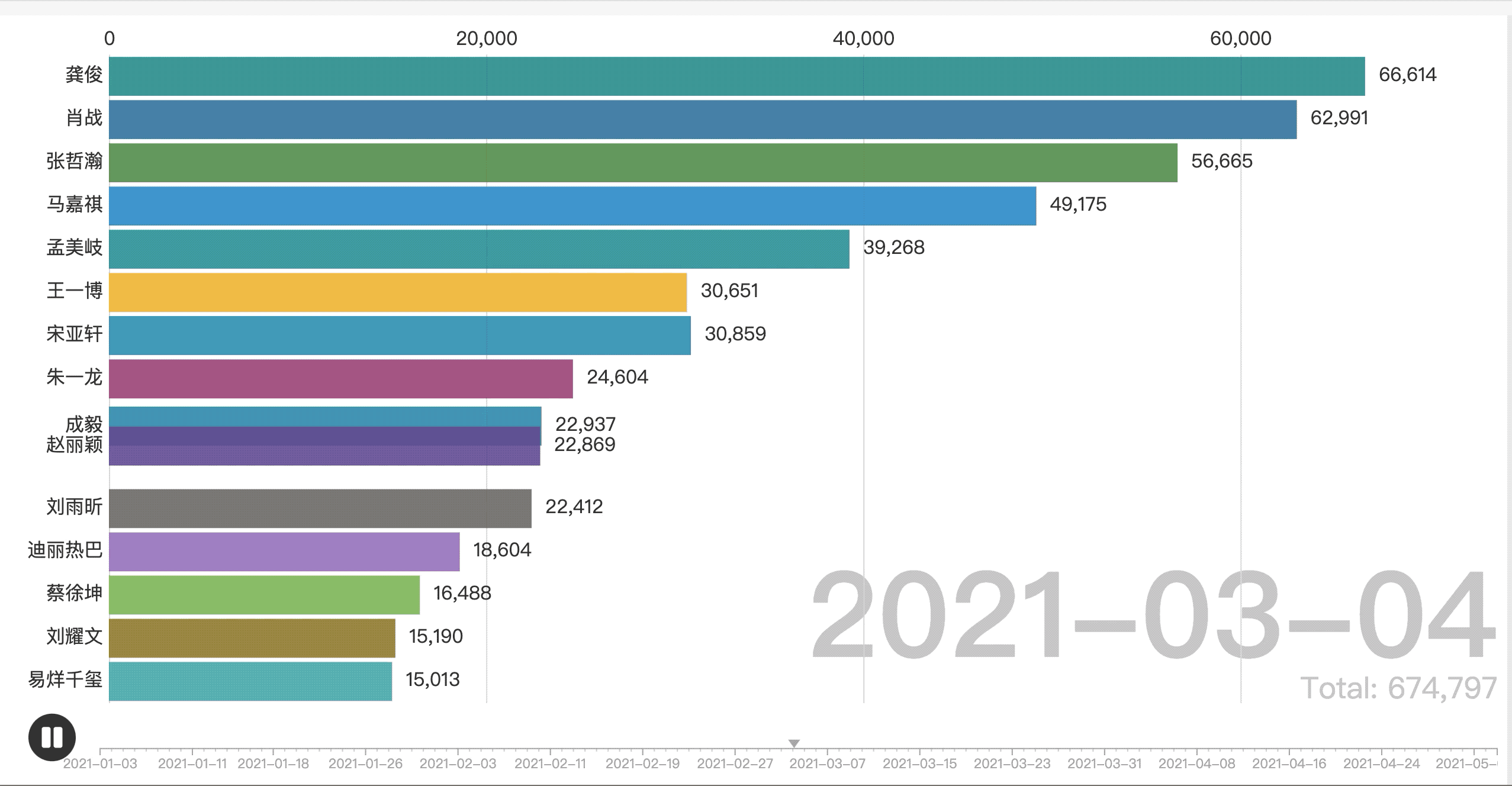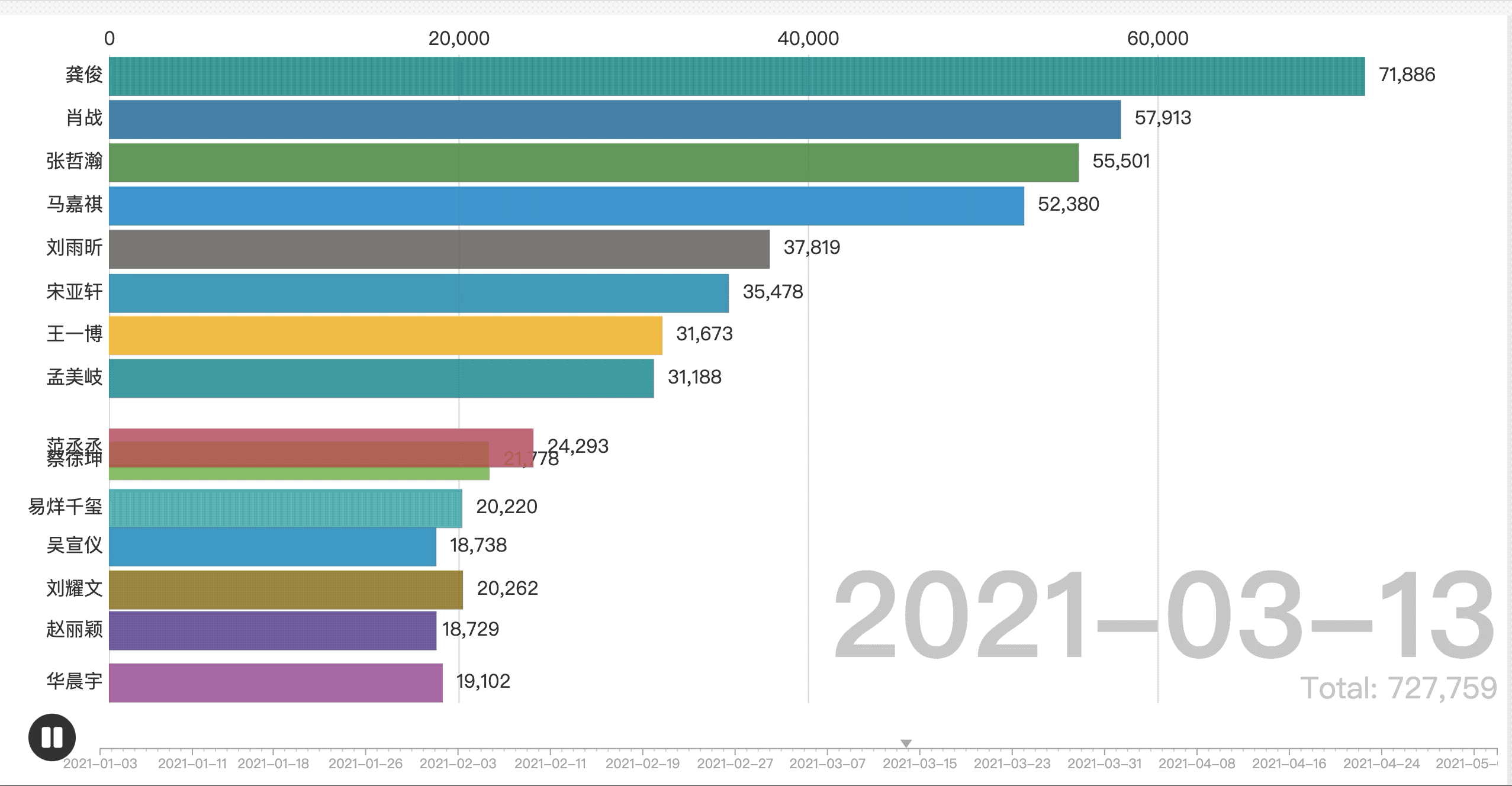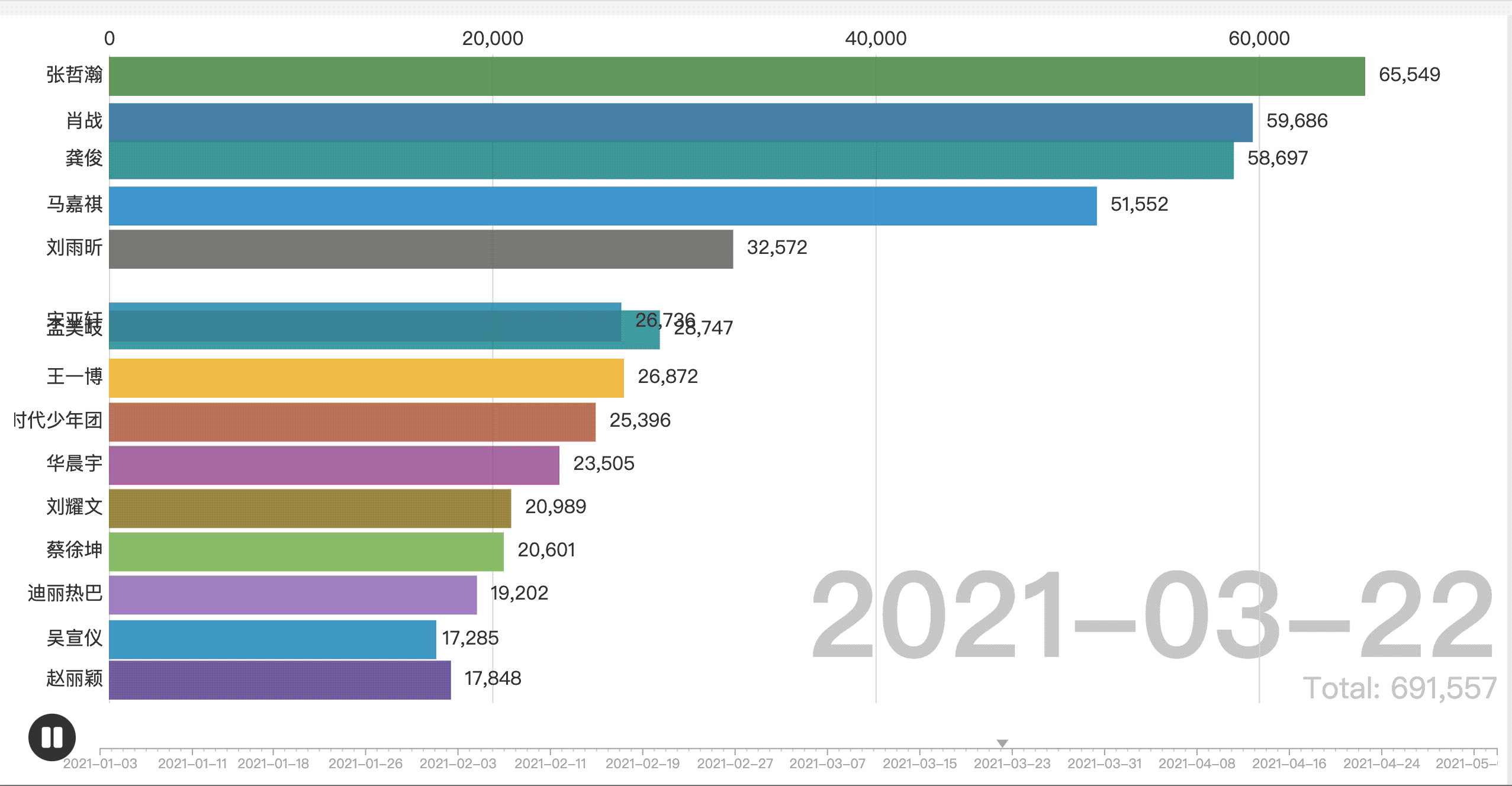发表自话题:明星热度排行榜
参考: B站_葩葩数据_2021年4月流量明星百度搜索指数动态排名.
小姐姐讲的非常好,希望多多关注、点赞。
流程
1.微博爬取排名前120的明星2.百度指数获取明星热度值3.flourish生成动态排行明星排行数据来源: 微博-超话排行-明星.
明星热度数据来源: 百度指数.
动态排行生成工具: flourish Bar chart race.
1.微博爬取排名前120的明星
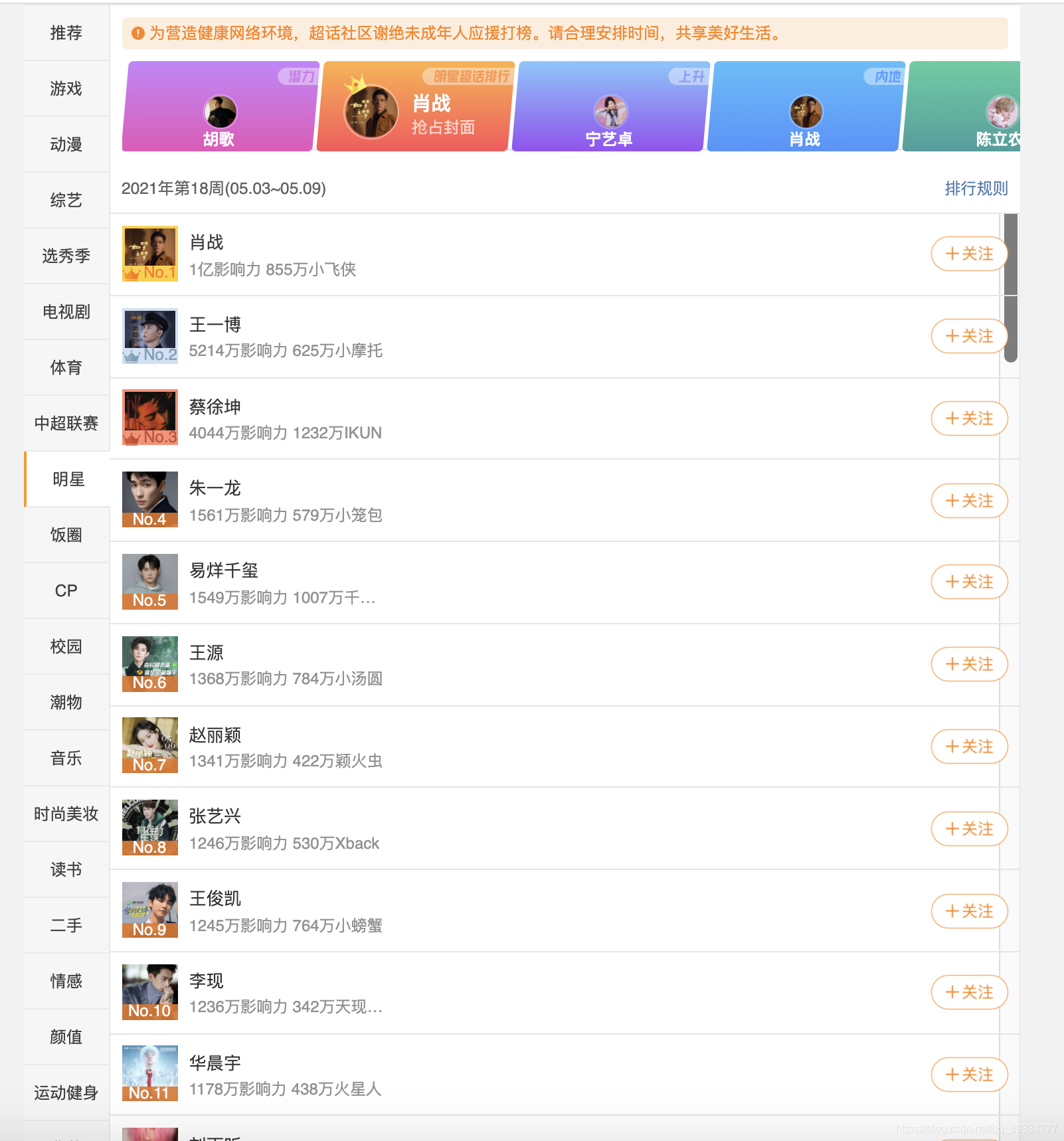
运行结果:
2.百度指数获取明星热度值
headers = { "user-agent":"自己的user-agent", "cookie":'自己的cookie' } # 爬取百度指数每日值(需要解码,可一次爬取大量数据) def decrypt(ptbk, data): d = {} res = [] for i in range(len(ptbk)//2): d[ptbk[i]] = ptbk[len(ptbk)//2 + i] for x in data: res.append(d[x]) return "".join(res) def get_ptbk(uniqid): url = 'https://index.baidu.com/Interface/ptbk?uniqid={}'.format(uniqid) response = requests.get(url=url, headers=headers).text whh = demjson.encode(response, encoding='utf-8') h1 = json.loads(whh) h2 = json.loads(h1).get("data") return h2 def get_dailydata(keyword, start, end): url = f'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22{keyword}%22,%22wordType%22:1%7D]]&startDate={start}&endDate={end}' res = requests.get(url, headers=headers) j = res.json() uniqid = j.get('data').get('uniqid') ptbk = get_ptbk(uniqid) data = j.get('data').get('userIndexes')[0].get('all').get('data') res = decrypt(ptbk, data) return res # 爬取多人的百度指数并制作成字典 def make_dict(name_list, sy, sm, sd, ey, em, ed): start = str(dt.date(sy, sm, sd)) end = str(dt.date(ey, em, ed)) data_dict = {} for name in name_list: print(name+" loading...") try: data_dict[name] = get_dailydata(name, start, end).split(',') except: break time.sleep(2) return data_dict data_d = make_dict(name_list, 2021,1,1,2021,5,4) start = dt.date(2021,1,1) end = dt.date(2021,5,5) # 注意:end要比抓取的end日期多一天 day_list = [] for i in range(start.toordinal(), end.toordinal()): day_list.append(str(dt.date.fromordinal(i))) df = pd.DataFrame(data_d, index=day_list) # 对空白数据进行填充 df.replace('','0',inplace=True) # 取当前日期和前两天的日期的平均值作为当天的热度值 df_rolling = df.rolling(window=3).mean().round(0) # 生成表格 根据flourish的需求需要将表格进行处理 df_rolling.transpose().to_excel("百度热度.xls")3.flourish生成动态排行
将生成的表格导入flourish中,效果图如下图所示: